
There’s a lot of hype around data right now. Businesses across the board are evaluating their approach to data. If they have a data stack, they’re trying to improve it. If they don’t have one, they’re looking at how to even begin. People want to be armed when they make business decisions at every level of the org.
Data is a core pillar for every future business. Teams focus on building this into a strategic advantage for every company, and each of them are on a journey from being data-aware to data-driven. No doubt there will be more changes in data and analytics in the next 5 years than there have been in the last 15 years.
Moreover, the modern data stack — whether it’s best-of-breed or all-in-one — is evolving as new technologies are developed. We’ve seen a shift from first generation data products to the solutions of today.
Where are we today?
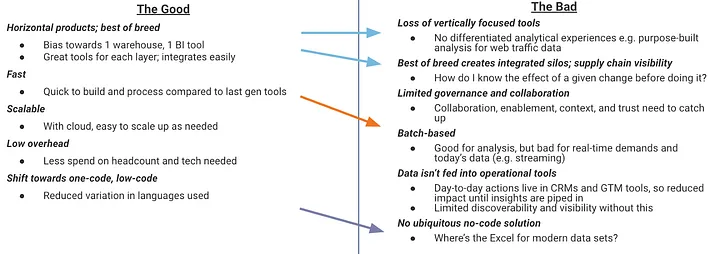
We’ve solved for the repetitive tasks that aren’t value additive. Building data pipelines. Transforming data. These are all immensely easier today. There’s been a ton of innovation here the past decade. That’s left us with a mix of good and bad. We have great products that solve for each layer of the data stack; companies can integrate best-of-breed systems. But that’s created a lack of vertically focused tools; we don’t have differentiated analytical experiences that are purpose-built for a specific use case or function (e.g. GTM analysis). Moreover, we’ve created supply chain issues where we lack visibility and can’t understand what a given change in one system will do both upstream and downstream.

Predictions
As an operator, I saw the power of great data platforms, and I knew this was an area I wanted to dive into more as an investor. After chatting with a bunch of friends and former colleagues, here are a few of my predictions for data and analytics for the next 3 to 5 years. I picked that timeframe because it gives us an opportunity to see true trends and shifts without being too open ended. And if I’m wrong, please feel free to hold me to it!


#1 Data as product
Data teams are becoming Product teams and they need the tools to go with that. As the scale and complexity of data platforms rises, leaders are applying software development best practices to data teams. This has already happened with CRM development and I witnessed it first hand; these teams have product owners, scrum masters, and QA. Data will be the 3rd pillar of modern businesses where we apply these same strategies and practices.
We’ll see software that lets teams manage data platform development and get closer to the dream of continuous integration and deployment. There will be a GitLab for data engineering teams. Teams will structure themselves with product owners, engineers, and scrum masters. Leaders will look for flexible, reliable development platforms that give them an opportunity to measure team performance, manage merges, and roll back changes if needed.
Product development best practices will be seen in the data team’s roles and responsibilities, processes, and technologies. We’ll see a suite of tools that power data teams to work more effectively and efficiently and they’ll look like some of the tools we already have today for software development.
#2 Failure of collaborative analysis
Data teams are overworked and their leaders are working to “free the data” to allow their stakeholders to self-serve asks. With the rise of low-code / no-code, we look to reduce reliance on proprietary languages and knowledge sharing. We’ve seen SQL-centered products win. But will there be an Excel or GSheets (let’s all admit this is far better for collaboration) for modern data sets? I don’t think so. There won’t be a ubiquitous no-code solution.
Companies buy BI platforms and teams work in those to build dashboards and publish analytics. The change management involved in introducing a collaborative analysis layer or data workspace upstream from the data visualization and output is too challenging for the vast majority of businesses. I know first hand that leaders don’t want another tool in their growing tech stack. If companies want to win in this space, they’ll have to have the BI & Analytics chops to compete against Looker and Tableau, and with the integrations to match to ensure insights are delivered to the places people are actually working. There need to be some combination of use cases to make this a product and not a feature. For example, they could combine with another core problem — like solving for the metrics layer.
There won’t be any winners for those building better data collaboration.
#3 Shift from best-of-breed to consolidation (all-in-one)
There’s been a shift from fragmented technology stacks to best-of-breed as we use the best technologies for each use case and look to maintain flexibility. As a result, we have supply chain issues where teams don’t understand the downstream implications of a given change and they don’t have a clear picture for security either. We’ve also created a ceiling for speed to insight as teams are reliant on the integrations and applications that’ve been built on batch-based processing.
Leaders have told me they’re tired of hearing that the best data teams can do is T+2 days for understanding key metrics. They want to know how the fiscal quarter ended within hours of it. Data companies have already begun to build in adjacencies as they look to deliver B- products to surround their A+ core. They’ve seen the enterprise demand for this as CIOs look to solve for business needs without multiplying their stack. The typical mid-size company already has 40–100+ SaaS applications! And competition is fierce in the market; data companies are looking to move past their single slice of the pie. Best-of-breed has always been great for the end user, but a pain for CIOs.
Many data companies move from collaborators to being frenemies as they build B- adjacent solutions to their core and look to capture more of the market.
#4 Data fabric and data mesh continues to be a dream
Leaders are focused on “free the data” and speed to insight. With modern technology, companies can acquire, transform, store, and analyze day in and day out. But when we compound the democratization of data with more SaaS applications, more data, more users, and more complexity, we kick off a new set of problems around context, transparency, discoverability, monitoring, reliability, privacy, collaboration, the list goes on.
1st Set (the basics):
Acquire + Transform + Store + Analyze
2nd Set (next set of problems):
Quality, Catalog, Lineage, Metadata, Privacy, DevOps
Like how software engineering teams develop tech debt, analytics teams develop data debt. Teams need to know which versions of metrics to use, the context for a manual override for the AOV of a given contract, and who should have access to what. Another emerging problem given the rise of data privacy and ownership: how do you remove data from specific AI models or copied data sets?
Without comprehensively solving for this next set of problems, the data fabric and the data mesh continue to be aspirational. With the pressure of “free the data” and speed to insight, companies are inadvertently building more data silos and there are no simple tried and true technologies to solve for governance, security, and discovery. Yes, there are tools today that solve for these, but they need to be simpler to use and have better UX to win broad appeal. The promise continues to be greater than the delivery.
We won’t see a realized enterprise data fabric or data mesh until we truly solve for this set of problems first.
#5 Rise of data discovery and catalogs
Even though that next set of problems won’t be solved in the next few years, I’m excited to see startups already working to solve some of these with simple and elegant solutions. Everything from data quality applications to data privacy solutions. The technologies being developed today will chip off 1–2 from this set of problems. But what’s a feature and what’s a product? I believe solving for the metrics layer — the discovery and documentation — will be the first to move from nice to have to need to have.
Understanding which metrics to use, what’s actually available, where to find them, what to trust, and the context for anomalies is a huge need. Data teams are using a variety of tools at different parts of the data stack to drive metrics. One analyst might be building a report in Salesforce while another is creating the same metric in Looker. With the democratization of data, data is becoming more siloed. Teams are tired of stitching this together with documentation via GDocs or GSheets and want a modern solution for discoverability, cataloging, and governance.
This also creates an exciting opportunity for companies building downstream to displace data storage and analysis. The shape and schema of the core data set should include metadata related to metrics definitions, trust, location, and other context. And tools like Looker and Tableau aren’t built to ingest this well. They’ll need to retrofit (this is hard), creating an opportunity for companies to build for the modern use case of metrics plus metadata.
We’ll see winners and success from companies building modern solutions for data discovery and catalogs.
#6 Function specific all-in-one wins
The rise of best-of-breed and the lack of purpose-built tools for specific functions has created a big opportunity for function-specific data analysis and actions. Tools that can drive acquire + transform + store + analyze for specific use cases have an advantage in both speed and impact. They aren’t dependent on batch-based processing or multiple integrations. And by purpose-built, I mean either industry specific or function specific.
For industries like healthcare, financial services, and construction, they have their own unique set of data sources, schemas, and reporting needs. The ETL tools of today aren’t built for data acquisition from these industry specific data sources (e.g. health systems, Procore). We’re stuck at step one of the process: acquire. These industries also have their own set of needs for reporting, visualizations, and business intelligence — although I believe that’s a less lucrative problem to solve for currently. We’re also already seeing enterprise companies like Snowflake launch healthcare specific products.
On the function side, the most attractive entry points here are within sales and marketing. These are functions with tried and true performance and success metrics that have built BizOps teams to stitch this together with Excel and Looker. The leaders of these departments want to be able to quickly answer the same questions month over month. How did we do? What were the drivers? They also want visualizations, dashboards, and displays for their use cases that help drive these repeated conversations. And I know executives want this to both drive their business and to show their performance to the C-suite.
In fact, we’ve already seen this with product-led growth (PLG). PLG is just data-driven sales that’s actually plugged into sales tools and workflows. Teams don’t want to use Looker dashboards. Even if you’ve built the most powerful sales insights engine, it’ll go neglected unless it feels like it’s designed for sales teams and fits into their workflows.


